Java 内存模型 (Java Memory Model, JMM) 很复杂,它涉及Java同步机制、编译器、JVM、CPU架构等多方面的内容。不同类别的程序员对 JMM 的关注重点自然是不一样的,这篇文章写的是一个普通 Java 程序员对 JMM 的理解。
1. 为什么需要JMM?
1.1 平台内存模型
在共享内存的多处理器体系结构中,每个处理器都有自己的缓存,并且定期地与主内存进行同步。但是不同的处理器架构提供了不同程度的缓存一致性 (cache coherence)。关于缓存一致性,我们可以设想两个极端:一个是允许不同的处理器在任意时刻对内存中同一个变量的观察值可以不相同;另一个极端是确保每一个处理器在任一时刻都知道其余的处理器都在做些什么。显然,这两种极端情况都很不理想,绝大多数平台提供的缓存一致性都位于这两者之间,并且还提供了一些指令来加强缓存和主内存的协同,这些指令我们称之为内存屏障 (memory barriers or fences)。
为了使 Java 程序员不需要关心不同架构之间内存模型上的差异,Java 提出了自己的内存模型。JVM 通过在合适的位置插入内存屏障,弥补了 JMM 和底层平台内存模型之间的差异。
1.2 可见性
假如一个线程 A 为变量 variable 赋值variable = 3,在缺少同步的情况下,另一个线程 B 可能无法立即看到线程 A 的操作,甚至是永远也看不到。原因有许多,比如缓存未刷新到主内存,又或者是线程 B 关于 variable 的缓存未失效。举个例子,来看看可见性对程序正确性的影响。
1 | public class NoVisibility { |
这个程序很简单,我们创建了两个线程,每个线程的任务都是对 count 自增 10000 次。我们期望最终的结果是 20000,但是很可惜,每次运行的结果都小于等于 20000,并且运行的结果都可能不同。其原因是,在缺乏同步的情况下,线程 t1 对变量 count 的操作可能对线程 t2 是不可见的,同理,线程 t2 对变量 count 的操作可能对线程 t1 也是不可见的。(在这个例子中,原子性也是导致结果小于 20000 的一个原因,这里暂时不讨论)。
为了避免这样的问题发生,在 Java 语法层面上,我们需要使用正确的同步机制;JVM 会根据 JMM 定义的规则在正确的位置上插入相关平台的内存屏障,以此来保证变量的可见性。
1.3 重排序
为了充分利用多处理器的运算能力,Java 语言规范只要求 JVM 实现线程内串行语义 (within-thread as-if-serial semantics),也就是说只要在该线程内程序的最终结果与串行执行的结果一致就可以了。这就给编译器,运行时以及 CPU 提供了很大的优化空间。但在其他线程看起来,程序可能就完全是乱序执行的。举个例子:
1 | public class PossibleReordering { |
很容易想到这个程序可能会输出 (1, 0),(0, 1) 或者 (1, 1):t2 执行完后 t1 才开始执行,t1 执行完后 t2 才开始执行,或者是 t1 和 t2 交替执行。但奇怪的是, PossibleReordering 还可能输出 (0, 0)! 原因可能有以下两个:
- 线程内执行的代码之间没有数据依赖性,因此它们可以乱序执行。
- 线程内的代码是顺序执行的,但是缓存刷新到主内存的时序与写入缓存的时序相反。
不管是哪种原因导致的,我们都把这种现象称为重排序。
重排序可能会影响程序的正确性,因此,我们必须通过同步机制限制编译器,运行时和 CPU 对指令进行重排序。JVM 会根据 JMM 定义的规则在正确的位置上插入平台相关的内存屏障,以此来限制指令的重排序。
2. Java内存模型简介
JMM 制定了一组确保可见性,限制重排序的规则。这组规则定义了操作之间一种称为 happens-before 的偏序关系。操作包括:对变量的读/写操作,监视器的加锁/释放锁,以及线程的启动和join等。要想执行操作 B 的线程能够看到操作 A 的结果 (无论 A 和 B 是否在同一个线程中执行),那么 A 必须 happens-before B。如果两个操作之间没有 happens-before 关系,那么 JVM 可以随意地对他们进行重排序。
Happens-before 规则:
- Program order rule. 在单个线程内,按照程序控制流程的顺序,书写在前面的操作 happens-before 书写在后面的操作。
- Monitor lock rule. 一个 unlock 操作 happens-before 后面对同一个锁的 lock 操作。
- Volatile variable rule. 对一个 volatile 变量的写操作 happens-before 后面对这个变量的读操作。
- Thread start rule. 对一个线程对象调用 Thread.start 方法 happens-before 该线程对象中的每一个操作。
- Thread termination rule. 线程 A 的所有操作都 happens-before 线程 B 对线程 A 的终止检测操作,也就是说线程 B 检测到线程 A 已经终止了,比如 Thread.join 成功返回,或者 Thread.isAlive 返回 false.
- Interruption rule. 线程 A 对线程 B 的中断操作 (Thread.interrupt) happens-before 线程 B 检测到中断发生 (可能抛出中断异常,Thread.isInterrupted 和 Thread.interrupted 返回 true)。
- Finalizer rule. 一个对象的初始化完成 (构造函数执行结束) happens-before 它的 Object.finalizer 方法的开始。
- Transitivity. 如果操作 A happens-before 操作 B,操作 B happens-before 操作 C,那么操作 A happens-before 操作 C。
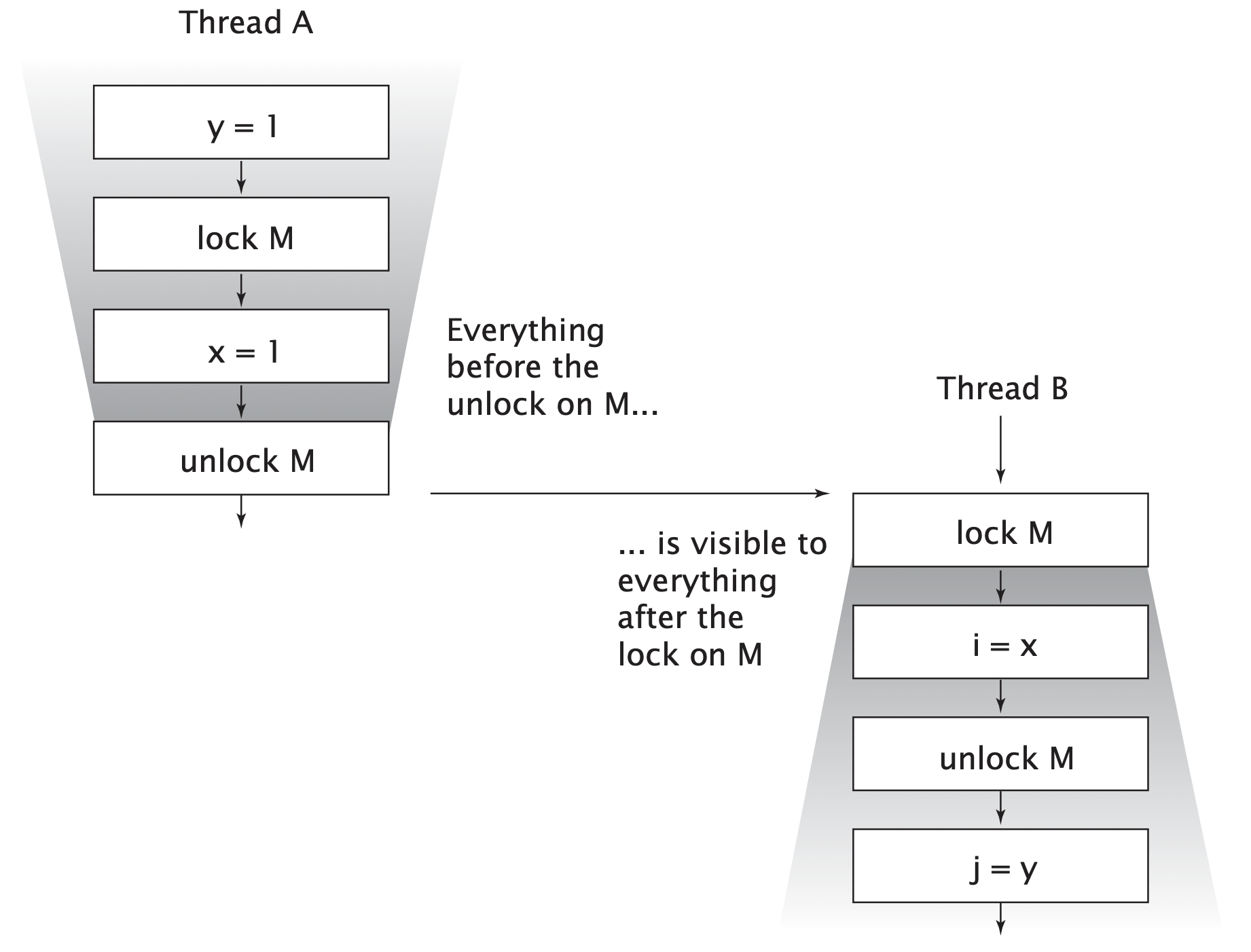
下面我们以 Monitor lock rule 规则为例,解释下 happens-before 到底是怎样一种关系。如果所示,线程 A 和 线程 B 使用锁 M 进行同步,线程 A 释放锁之后,线程随后获取到了锁。那么线程 A 在释放锁之前的所有操作对线程 B 都是可见的,并且在线程 B 看来线程 A 中释放锁之前的操作都是按程序顺序执行的,也就是说 happens-before 规则不仅仅保证了可见性,也限制了重排序。线程 A 释放之后的操作与线程 B 获取锁的操作没有 happens-before 关系,也就是说线程 A 释放锁之后的操作对线程 B 来说可能是不可见的,也可能在线程 B 看来是乱序执行的。
3. 对象发布
3.1 不安全的发布
当缺少 happens-before 关系时,就可能出现重排序问题,这就解释了为什么在没有充分同步的情况下发布一个对象会导致另一个线程看到一个部分构造的对象 (partially constructed object). 我们以一个经典的例子——延迟初始化,来说明这个问题。
初看起来,这个程序好像只存在 check-then-act 竞态条件问题。假设所有的 Resource 对象都是一样的,并且我们也不在乎创建多个 Resource 对象。UnsafeLazyInitialization 依然是不安全的,因为另一个线程可能看到一个部分构造的 Resource 实例。
1 | public class UnsafeLazyInitialization { |
在初始化一个对象时,需要写入多个变量,给对象的属性赋初始值;发布一个引用也需要写入一个变量,即把新对象的地址值赋值给引用。如果我们无法确保发布引用 happens-before 另一个线程加载该引用,那么在另一个线程看来,给对象属性进行初始化和给引用变量赋值可能是乱序执行的。也就是说,另一个线程可能看到引用的最新值,但看到的对象属性值却是过时的——即一个部分构造的对象。
假设线程 A 是第一个调用 getInstance 的线程,它看到 resource 为 null,因此将实例化一个 Resource 对象,并用 resource 去引用这个新对象。随后,线程 B 调用 getInstance,它可能看到 resource 的值非空,因此使用这个已经"构造好"的 Resource 实例,但线程 B 可能看到的只是一个被部分构造的实例——并且我们无法预料该实例的状态随后是否会发生变化。
除了不可变对象之外,不安全的发布是非常危险的。
3.2 安全的初始化模式
有时候,为了提高程序的响应性,我们需要对高开销的对象进行延迟初始化。但是,我们在 UnsafeLazyInitialization 中看到了错误的延迟初始化可能会给程序带来不可预料的问题。那么怎么修复这样的问题呢?答案是,使用正确的同步机制。
3.2.1 同步方法
最简单的办法就是给 UnsafeLazyInitialization.getInstance 加上 synchronized. 但是这样的话,所有访问 getInstance 的线程只能串行执行。但是当竞争激烈的时候,这会严重影响到程序的性能。
1 | public class SafeLazyInitialization { |
3.2.2 Double-checked locking
可能有很多同学会觉得,除了第一次创建对象我们应该同步 (避免创建多个对象),随后对 resource 的访问就可以不同步了 (毕竟我们只是访问数据,并未修改数据),这种想法催生了臭名昭著的 double-checked locking 反模式。那么问题出现在哪里呢?我们一起来分析下:
1 | public class DoubleCheckedLocking { |
首先,在没有同步的情况下,检查是否需要初始化,如果 resource 引用不为 null,就直接使用它。否则,在同步的情况下,再一次检查是否需要初始化,从而保证只有一个线程创建了 Resource 对象。这段代码的问题就出在,在常见的代码路径中 (resource 不等于 null),对 resource 引用的访问没有同步!因此线程可能看到一个部分构造的 Resource 对象。要修复这个问题也很简单,我们只需要保证对 resource 的写入 happens-before 随后对 resource 的读取,因此,我们只需要在上述代码中将 resource 声明为 volatile 类型即可。
尽量不要使用 double-checked locking,因为代码看起来很丑,而且晦涩难懂。
3.2.3 Lazy initialization holder class
我们有一种更好的延迟初始化方式——lazy initialization holder class 模式。这种模式利用了 JVM 的一些特性:1. JVM 会延迟加载类,也就是说只有当使用到这个类的时候才会加载;2. JVM 加载类并对类进行初始化的过程是线程安全的。
1 | public class ResourceFactory { |
当线程第一次调用 ResourceFactory.getInstance 方法时,JVM 会加载和初始化 ResourceHolder,在初始化的过程中会创建 Resource 实例。JVM 对类进行初始化的时候会获取一把锁,随后每个线程都会获取这把锁以确保这个类已经被加载,因此在静态初始化期间,对内存的写入操作对所有线程都是可见的。正是因为这个原因,lazy initialization holder class 模式不再需要额外的同步机制。
4. Initialization safety
我们知道不可变对象的状态是不能被修改的,因此它们天然是线程安全的对象,也就是说我们没必要对不可变对象进行同步。经过前面的讨论,我们知道在没有充分同步机制的情况下,对象的发布是不安全的,其他线程可能看到部分构造的对象。因此,我们需要额外的机制来保证,正确构造的不可变对象 (没有 this 逸出) 即使被不安全的发布,也能安全地被线程共用。
这种机制就是 initialization safety。Initilizaiton safety 可以保证,对一个正确构造的对象,不管该对象是不是被安全地发布,所有线程都能看到由构造函数给 final 域设置的初始值。并且那些从 final 域可达的变量 (比如 final 数组中的元素,或者是 final HashMap 中的键值对) 同样对所有线程都是可见的。
这意味着,下面代码中的 SafeStates 可以安全地发布,即使是通过 UnsafeLazyInitialization 中的方式发布,也没有任何问题。
1 | public class SafeStates { |
Initializaiton safety 有很多限制。
- 对象必须被正确构建,也就是说在构造函数中没有发生 this 逸出。否则,initializaition safety 将失效。
- Initialization safety 只能保证 final 域以及从 final 域可达变量构造完成时的可见性,也就是说所有线程都能看到由构造函数给它们设置的值。如果构造完成后,这些变量发生了修改,我们仍然需要同步机制保证可见性。
- Initialization safety 对那些非 final 域,以及从 final 域不可达的变量不做任何保证。
小结
这篇文章主要是围绕可见性和重排序展开的。首先介绍了在没有同步机制的情况下,可见性和重排序可能给程序带来一些千奇百怪的问题;以此引入了 Java 内存模型,Java 内存模型制定了一些规则 (happens-before),对可见性做出了些保证,对重排序做出了些限制;然后,我们探讨了可见性和重排序对发布对象的影响,不安全地发布一个可变对象是非常危险的;最后,由于不可变对象的特殊性,我们需要一套机制——Initialization Safety,使得不可变对象即使被不安全地发布,也可以被多个线程安全的共享。