上一篇文章我们分析了可见性和重排序对程序正确性的影响,并且举了个计数器的例子。那是否保证了可见性,限制重排序之后,程序就不会出问题了呢?如下代码所示,我们声明 count 变量为 volatile 类型,根据 happens-before 规则中的 volatile variable rule 可知,对 count 变量的写入 happens-before 随后对 count 变量的读取。那么该程序是不是就没问题了呢?运行之后,我们发现每次的结果依然是小于等于 20000,且每次的结果都可能不一样。那么问题出在哪呢?
1 | public class NoAtomicity { |
原因是 count++ 这个操作并不是原子的,这是一个典型的 read-modify-write 操作。如果出现下图所示的调度,线程 A 和 线程 B 都对 count 进行了自增操作,但 count 的最终结果是 1,出现了更新丢失。所以仅仅保证可见性,限制重排序是不足以保证程序正确的,我们还需要保证原子性。

使用 Java 提供的内置锁,或者显示锁,我们可以很容易地把 count++ 变成原子操作,这样做在没有锁竞争,或者锁竞争程度适当的情况下,性能还是不错的 (Java 在 1.6 版本对内置锁做了很大的改善,大大提升了内置锁在没有竞争,或者竞争程度适当情况下的性能)。但若锁竞争比较激烈,那么线程将被挂起,等待被唤醒。线程调度,上下文切换等操作的开销远远大于执行 count++ 的开销,调度开销与工作开销的比值会非常高,也就是说宝贵的 CPU 资源大部分浪费在调度工作上了。
对于细粒度的操作 (比如 count++, 容器类中的大部分简单的方法等),使用锁进行同步,在竞争激烈的情况下,性能会大打折扣。volatile 是一种更轻量级的同步机制,它在访问变量的时候不会涉及线程调度和上下文切换等操作,但是它不能保证复合操作的原子性。
那有没有一种同步机制介于这两者之间,即可以像 volatile 一样访问变量 (发生竞争的时候,线程不会被挂起),又可以像锁一样为简单的复合操作提供原子性?幸运的是,在现代处理器中提供了这种机制。
1. 硬件对并发的支持
排他锁的思想比较悲观,它认为如果不上锁,就一定会发生并发问题。因此它采用一种保守的策略:不管有没有竞争,我都上锁,以防万一。这种思想适用于竞争激烈以及操作粒度大的情况。
对于细粒度的操作,有一种更好的思想,那就是乐观的思想:我们有一种侦测的手段 (冲突检查)可以侦测到在执行更新操作的时候,是否有来自其他线程的干扰。如果有,那么这个更新操作无效,并且我们可以重试 (也可以不重试);如果没有,那么这个更新操作有效。
处理器工程师很早就意识到了这个问题,在早期的处理器中就提供了原子的 test-and-set, fetch-and-increment, swap 等指令。我们可以用这些指令来实现 mutexes 和一些更为复杂的并发对象 (concurrent objects)。如今,几乎所有的现代处理器都提供了更为强大的指令,比如 compare-and -swap, load-linked/store-conditional,这些指令可以提供原子的 read-modify-write 操作。
大多数处理器架构都选择提供 compare-and-swap (CAS) 指令,并且 Java 也是以 CAS 的形式使用这些指令的。CAS 有 3 个操作数—— 内存地址 V,期望的旧值 A,和待写入的新值 B。如果 V 的值和 A 相等,那么 CAS 会把 V 的值更新为 B,否则它什么也不做;不管哪种情况,CAS 都会返回现在 V 中的值。CAS 还有一种变种形式,叫做 compare-and-set,它会返回更新操作是否成功。文字描述可能比较晦涩,我们用 Java 代码来说明 CAS 的语义。
1 | public class SimulatedCAS { |
CAS 的含义是:我认为 V 现在的值应该是 A,如果是,那么将 V 的值更新为 B;如果不是,那么不修改,但是你得告诉我 V 现在的值是多少。
CAS 采用的是乐观的思想,它会尝试更新操作,并在更新的过程中检测其他线程是否修改过这个变量。当多个线程同时使用 CAS 更新一个变量的时候,只有一个线程能成功,其他线程都将失败。然而失败的线程不会被挂起,而是被告知在这次竞争中失败了。它们可以决定再次尝试,或者是执行一些恢复操作,又或者是不再尝试了。失败的线程不会被挂起,而是由程序员决定该如何处理,这就能避免由锁带来的一些问题,比如死锁和优先级反转 (不过依然存在活锁和饥饿的风险)。
在 Java 5.0 之前,我们必须编写 native 代码才能确保处理器执行 CAS 操作;Java 5.0 提供了原子变量类 (AtomicXxx),可以让我们很方便的在 int, long 和引用类型上执行 CAS 操作;Java 9 提供了VarHandle,它可以让我们更灵活更高效地使用 CAS (这里我们不做介绍)。
2. 原子变量类
相对锁来说,原子变量粒度更细,量级更轻,对于构建高性能的并发程序至关重要。从某种意义上讲,原子变量就是"更好的"volatile 变量——它的内存语义和 volatile 一样,并且提供了一些原子的更新操作。以 AtomicInteger 为例,AtomicInteger 表示一个 int 类型的值,我们可以用 get 和 set 方法对原子变量进行读取和写入,并且这些读/写操作有着和 volatile 变量一样的内存语义 (volatile variable rule)。除此之外,它还提供了原子的 compareAndSet 方法,以及原子的算术方法,比如加法,递增,递减等。
Java 一共有 12 个原子变量类型,我们可以把它们分成四类:标量类 (scalars),域更新器类 (field updaters),数组类 (arrays),和复合变量类 (compound variables)。所有这些原子变量类都支持 CAS 操作,AtomicInteger 和 AtomicLong 还支持简单的原子算数操作。
最常用的自然就是标量类,共有四种:AtomicInteger, AtomicLong, AtomicBoolean 和 AtomicReference。(我们可以将 byte, short 转换成 int, 通过 floatToIntBits 和 doubleToLongBits 将浮点数转换成 int 和 long,从而可以使用原子类的功能)。
原子数组类有三种,只支持 int[], long[] 以及引用数组。原子数组类的作用相当于把数组元素都声明为对应的标量类。比如 AtomicIntegerArray 的作用就相当于把它里面的元素都声明为了 AtomicInteger 类型。
其余的原子变量类型,我们在相应的使用场景中会做简单的介绍。
2.1 NumberRange
接下来,我们以一个简单的例子来说明下原子变量的正确使用方式。假设我们需要设计一个表示整数区间的类 NumberRange,它有两个属性 lower 和 upper,并且我们有一个约束条件:lower 必须小于等于 upper。我们很容易就写出下面的代码。
1 | public class SynchronizedNumberRange { |
SynchronizedNumberRange 使用内置锁保证了数据的一致性,但它同时只允许一个线程访问该类的对象,在竞争激烈的情况下,性能会十分低下。那我们能不能够改善 SynchronizedNumberRange 的性能呢?首先,使用 volatile 是不行的,因为这里存在典型的 check-then-act 竞态条件。那我们可不可以使用原子变量呢?我们先尝试一下:
1 | public class UnsafeNumberRange { |
很明显,UnsafeNumberRange 依然存在 check-then-act 竞态条件,原子变量只能保证单个操作的原子性。所以 UnsafeNumberRange 是线程不安全的。
难道我们就没有其他办法了吗,只能忍受锁带来巨大的开销?既然原子变量只能保证单个变量操作的原子性,那么我们是不是可以将 NumberRange 的两个属性封装到一个对象内,然后使用 AtomicReference 对这个对象进行更新操作…
1 | public class CasNumberRange { |
当多个变量组成的不变性条件 (invariant) 的时候,我们往往将这多个变量封装到一个对象内,然后采用自旋 CAS 的方式给它们一起赋值,以此来保证多个赋值操作的原子性,如 CasNumberRange 中所做的一样。
3. 非阻塞算法
基于锁的算法可能会发生各种活跃性故障。如果一个线程在持有锁的期间,由于阻塞 I/O,内存页缺失,或者由于其他原因而导致延迟执行,那么很可能其他线程也不能够执行。如果在某种算法中,一个线程的失败或者挂起不会引起另一个线程的失败或者挂起,那么这种算法我们就称之为非阻塞算法。如果在算法中,只使用 CAS 来协调线程之间的操作,那么这个算法一定是非阻塞算法。我们已经看到了一个非阻塞算法:CasNumberRange。从中我们可以发现实现非阻塞算法的关键在于:如何将原子修改操作的范围缩小到单个变量上,同时还保持了数据的一致性。
接下来,我们以简单的数据结构——栈和队列为例,窥探下非阻塞算法是如何应用到数据结构上的。
3.1 非阻塞栈
栈是最简单的链式结构:每个元素只被一个引用指向,并且它最多指向另外一个元素。栈最重要的两个操作——push 和 pop——都只需要原子地修改 top 指针即可,因此非阻塞栈的实现是比较简单的。
1 | public class ConcurrentStack <E> { |
3.2 非阻塞队列
队列比栈要复杂,因为队列必须维持头尾两个指针,并且有两个引用指向尾节点——尾节点前一个节点的 next 指针,以及 tail 指针。如果我们在队尾插入一个元素,那么我们必须保证这两个指针被原子地更新。否则的话,如果一个指针更新成功了,另一个指针更新失败了,那么队列就会处于一个不一致的状态;又或者是两个指针都更新成功了,但是在这两个指针更新的过程中,另一个线程也更新了 next 指针或着 tail 指针,队列同样会处于一个不一致的状态。并且尾节点前一个节点的 next 指针和 tail 指针好像也没什么不变性条件,把它们封装成一个对象看起来有些不伦不类。这样看起来 put 操作好像是没法通过 CAS 来完成了。
我们需要一些特别的技巧。如果一个操作有多个步骤,并且我们有办法判断这个操作是否处于中间状态。那么我们就可以采用这样一种策略:当线程 B 到达的时候,如果它发现这个操作正处于中间状态,那么说明有某个线程 (线程 A) 正在执行这个操作,因此线程 B 知道它不能立即执行这个操作。它需要等待 (不断地检查是否处于中间状态) 线程 A 的完成。这样两个线程就不会发生干扰了。
这种方法可行,但是它和锁没有多大的区别 (其实这就是自旋锁的原理),它使得多个线程必须串行地访问数据结构。如果在这个过程中,线程 A 更新失败了,导致数据结构处于中间状态,那么其它线程都将无法执行这个操作。要想设计一个非阻塞算法,我们必须保证一个线程的失败,不会妨碍其它线程的执行。
第二种策略是:当线程 B 到达的时候,如果它发现线程 A 正在修改数据结构,并且如果线程 B 能够知道线程 A 执行到了哪一步,那么线程 B 可以"帮助"线程 A 完成它的更新操作,然后再执行自己的操作,而不是等待线程 A 完成。当线程 A 恢复后试图完成操作,它会发现有其它线程已经帮助它完成了。第二种策略需要比第一种策略知道更多的信息,线程不仅需要知道操作是否处于中间状态,还需要知道这个操作已经执行到了哪一步。
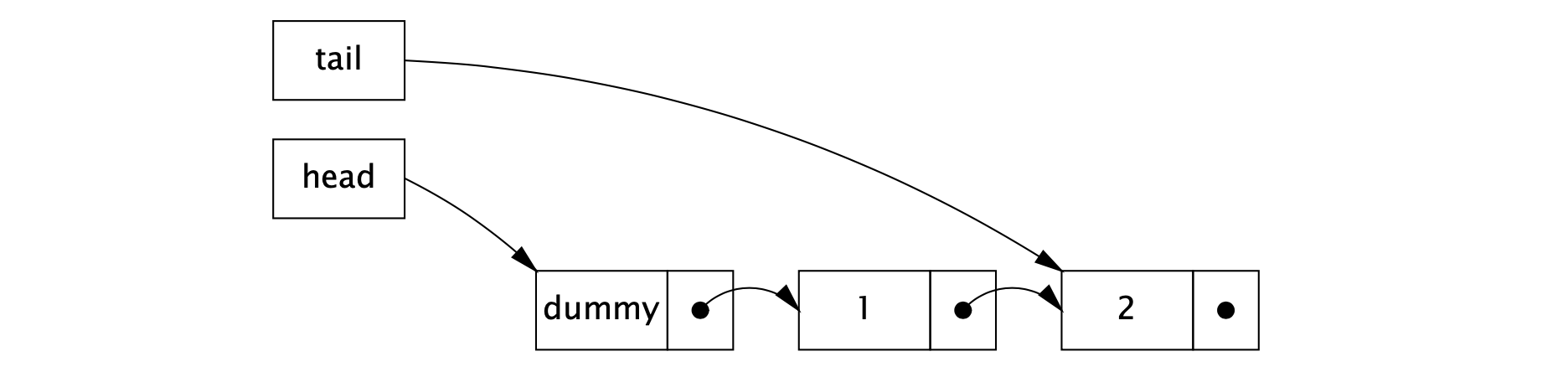
Michael-Scott 在 1996 年提出的非阻塞链接队列算法采用的正是第二种策略。下面代码中给出了它的插入方法的实现。在该算法中,我们包含了一个哨兵 (sentinel),又称为哑节点 (dummy node),这样做的目的避免一些边界条件的检查,简化代码的实现。head 指针永远指向哑节点,tail 指针有 3 种状态:指向哑节点 (此时队列为空),指向最后一个节点,指向倒数第二个节点 (当有其它线程在插入元素时)。第一种和第二种情况,队列处于正常状态 (quiescent state),第三种情况,队列处于中间状态 (intermediate state)。下图展示的是在正常状态下,包含两个元素的队列。
当插入一个新元素的时候,我们需要更新两个指针。首先将最后一个节点的 next 指针指向新插入的节点,其次再将 tail 指针指向新插入的节点。该过程只包含两个步骤,如果我们能判断插入操作处于中间状态,那么我们也就知道它执行到哪一步了,所以关键在于如何判断插入操作是否处于中间状态。如果队列处于正常状态,那么 tail 指针指向节点的 next 域为 null;如果队列处于中间状态,那么 tail 指针指向节点的 next 域不等于 null。因此,任意一个线程都可以通过检查 tail.next 获取队列当前状态。如果当前处于中间状态,那么该线程可以将 tail 指针往前移动一个位置,从而帮助另一个线程完成插入操作。下图展示的是处于中间状态下的队列。
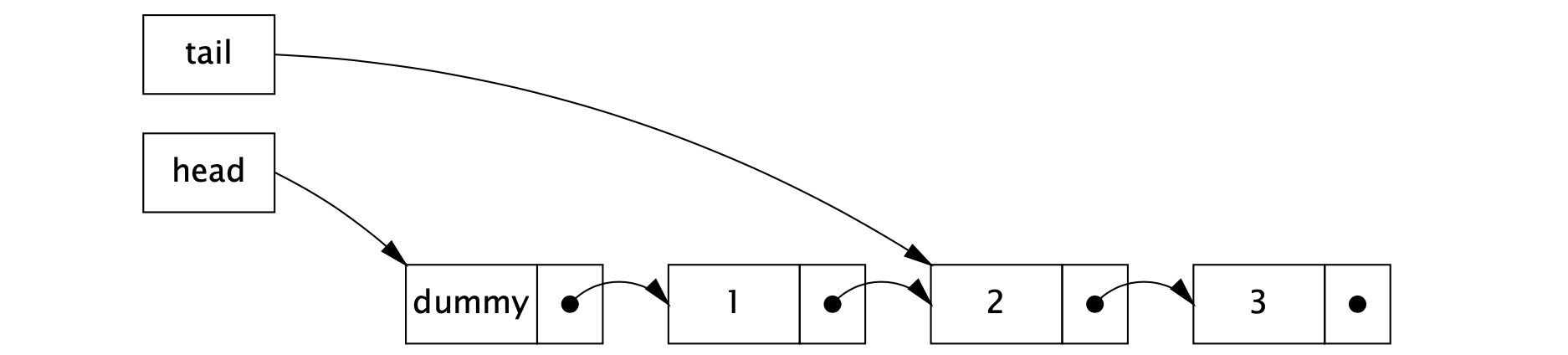
LinkQueue 在插入新元素之前,首先检查队列是否处于中间状态 (步骤 A)。如果是,那么有另一个线程正在插入元素 (处于步骤 C 和 D 之间),该线程会通过 CAS 尝试帮它完成操作 (步骤 B),并重新尝试插入新元素。如果队列处于正常状态,那么该线程会通过 CAS 尝试把新节点链接到队列的末尾 (步骤 C),如果失败,线程会重新尝试插入新元素;如果步骤 C 成功了,那么我们就认为插入生效了。将 tail 指针移动到新插入的元素 (步骤 D) 被认为是一个"清理操作",因为它即可以由插入该元素的线程完成,也可以由其它线程完成,因此不管步骤 D 有没有成功,方法都返回 true。
1 | public class LinkedQueue <E> { |
4. CAS 的缺点
虽然在绝大多数时候,CAS 都比锁的性能好,但 CAS 不是解决并发问题的银弹,它也有缺点:
- CAS 只能确保单个变量的修改操作是原子的。虽然我们可以利用聪明的算法 (比如LinkedQueue 中使用的算法),使多个变量的修改操作达到原子性的效果,但这是算法的功劳。
- 程序员必须处理竞争问题。一般来说我们有三种策略:重试,回退,放弃。
- 在竞争极端激烈的情况下,CAS 和锁相比,性能可能更加低下。如果我们以自旋重试的方式使用 CAS,那么在竞争异常激烈时候,大部分线程都在自旋重试,消耗着 CPU 时钟和内存总线的同步通信量 (synchronization traffic)。这时候,更好的选择是把这些线程挂起,将资源让给其他线程使用。
- ABA 问题。CAS 的语义是:V 的值是否仍然为 A,如果是那么把 V 的值更新为 B。在大多数情况下,这就足够了;然而,在某些特殊情况下,我们需要知道 “至从上次观察到 V 的值为 A 以来,V 的值是否发生了变化”。在某些算法中,如果 V 的值由 A 变成 B,再由 B 变成 A,仍然被认为是发生了变化,这个问题称之为 ABA 问题。一种简单的解决方案是:我们给值贴上一个版本号,更新的时候,不仅更新 V 的值,也更新版本号。在 Java 中提供了 AtomicStampedReference 以及 AtomicMarkableReference 来支持这种解决方案,AtomicStampedReference 可以原子地更新 “引用-整数"二元组,因此我们可以为每个值贴上一个版本号;AtomicMarkableReference 可以原子地更新"引用-布尔值"二元组,这样我们就可以将某些对象标记为"已删除”,而不将它们从数据结构中剔除。
小结
这篇文章首先通过一个具体的例子,说明了原子操作对编写正确并发程序的重要性。计算机底层硬件通过一些并发原语 (比如 CAS) 提供了一些最基本的原子操作。Java 通过原子变量和 VarHandle 将这些并发原语统一以 CAS 的形式暴露给程序员使用。
我们可以通过 CAS 实现各种非阻塞算法,构建各种并发对象,从而为应用程序提供更好的可伸缩性 (scalability)。非阻塞算法被广泛地应用在操作系统和 JVM 中,用来实现线程和进程调度,垃圾回收,锁和各种并发数据结构。JVM 从一个版本升级到另一个版本,并发性能的提升主要来自于对非阻塞算法的使用。